A Markup Language Parser Illustrating Inheritance
Last year, I decided to learn C++. I thought it would be all about inheritance, but nothing I encountered really screamed “Inheritance” to me. Until I decided to do an XML parser.
Why would I write an XML parser, you may ask? Several reasons. I wanted to see how hard it was. Secondly, none of the free ones that I could find had a simple, compelling example. I'm talking something like this:
static bool enabled = false; // flag that controls the region from which we grab data
static bool printme = false; // finer flag indicating if content should be captured
static vector <string> strings;
void
Parse_FP::xml_content (string &c)
{
if (printme) {
strings.push_back (c);
}
}
void
Parse_FP::outcall_td (XML_Elements type, string &element, vector <XML_attribute> &attributes)
{
if (enabled) {
if (type == XML_ElementStart) {
printme = true;
} else if (type == XML_ElementEnd) {
printme = false;
}
}
}
void
Parse_FP::outcall_tr (XML_Elements type, string &element, vector <XML_attribute> &attributes)
{
if (type == XML_ElementStart && find_specific_attribute (attributes, "bgcolor", "#FFFFFF")) {
enabled = true;
strings.clear();
} else {
if (strings.size()) {
cout << "Data dump:\n";
for (auto i : strings) cout << "\"" << i << "\" ";
cout << "\n";
enabled = false;
printme = false;
}
}
}
Let's look at the three functions provided above. My goal was to parse an HTML document (a website) in order to scrape some information. In looking at the HTML code, I determined that the information gets interesting when there's a <tr bgcolor="#FFFFFF"> tag. So, in my outcall_tr function, I match that when I'm given an XML_ElementStart (the <tr> as opposed to the </tr>, which would be indicated with an XML_ElementEnd). Once found, I raise the enabled flag for further processing (and clear the current buffer of accumulated data, the strings vector).
The rest of the HTML file goes by, until I get the closing </tr> — at which point, I dump the data that I've accumulated, and lower the enabled (and printme) flags to inhibit processing.
As the HTML file is going by, I've requested to be notified about <td> elements (handled by the outcall_td function). If the enabled flag is raised, and I have an XML_ElementStart (that is, <td>), I raise a secondary flag called printme. At the end of each data set, (that is, when I hit the XML_ElementEnd version </td>), I lower the printme flag.
The printme flag is used in the xml_content function. If raised, I add the accumulated content (everything between the “>” and the “<” characters) to the strings vector, else I ignore it. Recall that the strings vector gets dumped in the </tr> processing in outcall_tr.
Easy peasy.
But.. but.. but...
Ok, let's get the complaints out of the way. HTML is not XML. I know. But they share enough in common that my basic XML parser parses HTML quite happily (it also does SGML — so well in fact that I found bugs, like “<idx<minor>” in my QNX books from 15 years ago!). The XML parser knows how to deal with elements (strings of characters surrounded by “<” and “>”), it knows how to accumulate attributes (the stuff that may optionally follow the strings of characters in elements — for example the “bgcolor="#FFFFFF"” part in the example above). It deals with comments (“<!--” through “-->”), CDATA sections (not relevant to HTML), directives (“<!” followed by text), and so on.
Let's take a look at the XML class in order to get a feel for how this works.
class Parse_XML
{
public:
/* constructor */ Parse_XML (string f);
/* constructor */ Parse_XML (void);
/* destructor */ ~Parse_XML (void);
void parse (void);
bool getc (char &c);
// markup section
virtual void xml_cdata (string &);
virtual void xml_comment (string &);
virtual void xml_directive (string &);
virtual void xml_element (XML_Elements, string &, vector <XML_attribute> &);
virtual void xml_instruction (string &, vector <XML_attribute> &);
// content section
virtual void xml_content (string &);
virtual void xml_EOF (void);
virtual void xml_Error (XML_Errors);
... // more stuff
};
My motto is simplicity. There are two constructors; one that takes a string (a filename), and one that reads from standard input. The function parse runs the state machine, relying on the getc function to get a character at a time from the input.
On further consideration, the getc should be virtual, that way I can allow derived classes to supply their own!
As the parse function runs, it takes the characters through a state machine (with 32 states), and
calls out through the member functions in the “markup” and “content” commented sections.
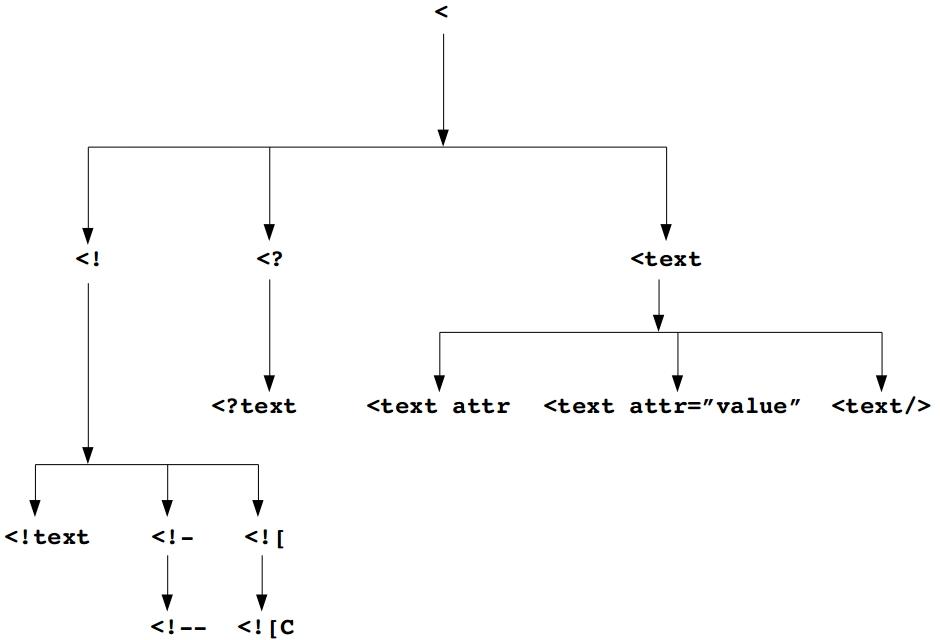
The initial state of the parser is Initial — in this state, it's looking for an opening angle bracket “<.” All other characters are accumulated into a string called content — this string gets dumped via the callout xml_content once an angle bracket is found, and represents all the text leading up to the angle bracket.
Once it finds the open angle bracket, the parser transits to state L (for “L”eft, indicating a left bracket was received). There, the next character is examined. It can be an exclamation mark (“<!”, in which case it transits to state LB for Left Bang), a question mark (“<?”, in which case it transits to state LQ for Left Question), or other, in which case we assume it's the beginning of an element (transit to state InElement).
From each state, further transitions are possible; LB transits to one of LBD (left bang dash), LBO (left bang open square bracket), or InDirective (to indicate that text should be accumulated to handle a directive, like “<!ELEMENT” to declare an element type).
For the purposes of HTML, however, the most important transitions are those directly out of the InElement state. Here, the HTML “tag” (e.g., “a,” “tr,” “table,” etc.) is accumulated into the element string, which gets dumped (along with any attribute/value pairs accumulated) via the outcall xml_element.
Returning to the example above, there's an HTML class that sits on top of the XML class, and it consumes elements (via the xml_element callout just mentioned) and figures out if the element is a <tr>, <td>, <table>, and so on. The vector of attributes consists of zero or more attributes that are within the element, and allows easy access for the users of the library.
Notice the Parse_FP::xml_content function. It gets the content from the XML base class directly (via inheritance). Also, you may notice that the Parse_FP class is neither XML nor HTML. It sits on top of the HTML class, which sits on top of the XML class.
Let's look at the HTML class (just selected portions, it's pretty big):
class Parse_HTML : public Parse_XML
{
public:
using Parse_XML::Parse_XML;
// incalls
virtual void xml_element (XML_Elements, string &, vector <XML_attribute> &);
virtual void xml_content (string &c);
// outcalls
virtual void outcall_a (XML_Elements, string &, vector <XML_attribute> &);
virtual void outcall_abbr (XML_Elements, string &, vector <XML_attribute> &);
virtual void outcall_article (XML_Elements, string &, vector <XML_attribute> &);
... // and a bunch more
virtual void outcall_title (XML_Elements, string &, vector <XML_attribute> &);
virtual void outcall_tr (XML_Elements, string &, vector <XML_attribute> &);
virtual void outcall_ul (XML_Elements, string &, vector <XML_attribute> &);
};
Finally — inheritance!
The Parse_HTML class derives from the Parse_XML class, and (because I'm using C++11), inherits the constructor as well (via the using Parse_XML::Parse_XML; statement).
The Parse_HTML class overrides the xml_element and xml_content functions, and provides outcalls for parsed HTML elements (the outcall_a through to outcall_ul functions). These functions are declared virtual so that someone else (we'll see this shortly) can override their functionality as required.
Who is this someone else? The highest-level parser, of course! In this case, it's Parse_FP:
class Parse_FP : public Parse_HTML
{
public:
using Parse_HTML::Parse_HTML;
virtual void xml_content (string &c);
virtual void outcall_td (XML_Elements, string &, vector <XML_attribute> &);
virtual void outcall_tr (XML_Elements, string &, vector <XML_attribute> &);
};
It inherits from the HTML class, and inherits the constructor as well, and then provides three virtual functions (xml_content, outcall_td, and outcall_tr), the implementation of which we've seen above.
Did I mention easy peasy?
For me, the true beauty of this approach is that the highest-level consumer (e.g., Parse_FP) supplies only the functions that it's interested in — three in this case. The other complexity is hidden in the base classes.
Compatibility
So far, I've tested this on two HTML webpages that I scrape regularly, an SGML document base that I used for my books, Wikipedia, Wiktionary, and the Ottawa Hydro “Green Button” (an XML formatted electricity usage scheme). For the XML ones (Wikipedia, Wiktionary, and the Green Button), I made a custom class that sits on top of the base Parse_XML class. The current SGML parser sits directly on top of the Parse_XML class as well.
Currently, (in the HTML parser) there's no concept of nesting or automatic closing (nesting as in, for example, a <table> within a <table>; automatic closing as in the implied </tr> when encountering another <tr> — quite important on its own, and will of course require nesting to work otherwise you wouldn't know which <tr> went with which <table>). These are relatively easy to add at their respective layers. Also, for the Wiki-based ones, I'd like to add a mid-level parser that knows how to deal with the wiki tags like [[Reference]] etc.
The thing I've learned here is:
Whatever looks the same to you at a given level of abstraction can simply be punted to the next higher level — let it figure out the subtle differences; it's going to be much better at it than you are.
This is important, because one of the things that's hard to get right is figuring out at what level of abstraction certain things should be handled.
For example, the base XML layer really doesn't care whether it's a <tr> or <td> or <table> element, it just knows it's an element. The next higher level up, the HTML layer, cares, and handles it. (Of course, the HTML layer really doesn't want to have to deal with parsing the “<” and “>” and other characters, or maintaining the state machine's state of whether it's currently in an element or an attribute or a comment, and so on.)
Higher and Higher
Looking at the XML structure for Wikipedia and Wiktionary, for example, shows higher and higher levels of abstraction. At the base XML level, there are the usual suspects: elements, comments, attributes, and so on. I created a two-level wiki class to handle these.
The bottom-most wiki class understands the structure of the document. Here's what a Wikipedia / Wiktionary document looks like (at this level, they're pretty much identical in terms of their XML structure):
<mediawiki ...>
<siteinfo>
...
</siteinfo>
<page>
<title>AccessibleComputing</title>
...
<revision>
...
<text xml:space="preserve">...</text>
<sha1>4ro7vvppa5kmm0o1egfjztzcwd0vabw</sha1>
</revision>
</page>
<page>
<title>Anarchism</title>
...
</page>
...
</mediawiki>
(I've left out a bunch of data — about 52 gigabytes, in fact :-))
The entire document is just one giant <mediawiki> data set, beginning to end. Within that are some administrative elements (e.g., the <siteinfo> which has a bunch of subordinates), and a whole bunch of <page> elements — these are the individual wikipedia pages.
Here's what the Wiki base class looks like:
class Parse_WikiBase : public Parse_XML
{
public:
using Parse_XML::Parse_XML;
// incalls
virtual void xml_element (XML_Elements, string &, vector <XML_attribute> &);
virtual void xml_content (string &c);
// outcalls
virtual void outcall_base (XML_Elements type, string &e, vector <XML_attribute> &a);
virtual void outcall_case (XML_Elements type, string &e, vector <XML_attribute> &a);
... // 22 more
virtual void outcall_text (XML_Elements type, string &e, vector <XML_attribute> &a);
virtual void outcall_timestamp (XML_Elements type, string &e, vector <XML_attribute> &a);
virtual void outcall_title (XML_Elements type, string &e, vector <XML_attribute> &a);
virtual void outcall_username (XML_Elements type, string &e, vector <XML_attribute> &a);
};
The outcalls it provides deal with the semantic information provided within the XML elements — for example, we see outcalls for our <title> and <text> elements.
As far as the data in the <title> and <text> goes, from the point of view of the Wiki parser, these “all look the same” — and that means it's time to apply my rule I mentioned above, “Whatever looks the same to you at a given level of abstraction, just punt it to the next higher level.”
So, in the next higher level of abstraction, we'd like to forget all about XML, and start dealing with the contents of pages, specifically, accumulating and indexing <title> elements and looking at the contents of the <text> elements.
As the French say, “plus ça change, plus c'est la même chose.” (“the more things change, the more they stay the same.”) Here's the next level — that is, the content of the <text> sections:
<text xml:space="preserve">
{{Redirect2|Anarchist|Anarchists|the fictional character|Anarchist (comics)|other
uses|Anarchists (disambiguation)}} {{pp-move-indef}} {{Use British English|date=January 2014}}
{{Anarchism sidebar}}
'''Anarchism''' is a [[political philosophy]]
...
{{cite journal |url=http://www.theglobeandmail.com/servlet/story/RTGAM.20070514.wxlanarchist14/BNStory/lifeWork/home/
|archiveurl=https://web.archive.org/web/20070516094548/http://www.theglobeandmail.com/servlet/story/RTGAM.20070514.wxlanarchist14/BNStory/lifeWork/home
|archivedate=16 May 2007 |deadurl=yes |title=Working for The Man |journal=[[The Globe and Mail]]
|accessdate=14 April 2008 |last=Agrell |first=Siri |date=14 May 2007 |ref=harv }}
...
==Etymology and terminology==
{{Related articles|Anarchist terminology}}
...
</text>
That's quite a complicated markup! Let's look at the elements individually, removing the extra stuff:
<text xml:space="preserve">
{{Redirect2...}}
{{pp-move-indef}}
{{Use British English...}}
{{Anarchism sidebar}}
'''Anarchism''' is a [[political philosophy]]
...
{{cite journal...}}
...
==Etymology and terminology==
{{Related articles...}}
...
</text>
It's like another whole markup language unto itself (well, yes — it actually is just that). It's called Wiki markup, and I've reduced the complicated example to three different colours:
- red indicates a “template” — Wiki has all kinds of them, for doing things like converting measurements, redirections, sidebars, bar graphs, date formats, etc.
- magenta indicates a hyperlink
- blue indicates formatting content, like HTML's <h1>, <h2>, etc.
Even the quoting (the use of the “'''” triple single quote) is part of the Wiki markup language.
I haven't finished my Wiki language parser, so I'll come back here when I've done that.